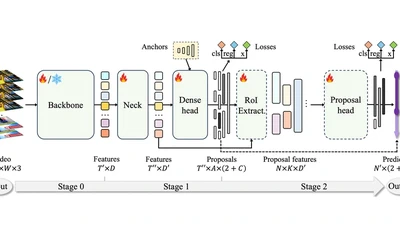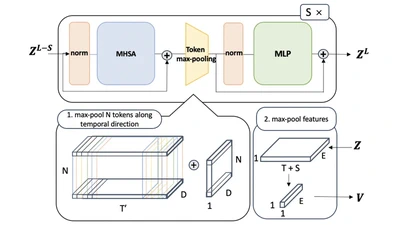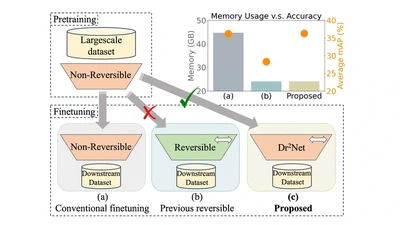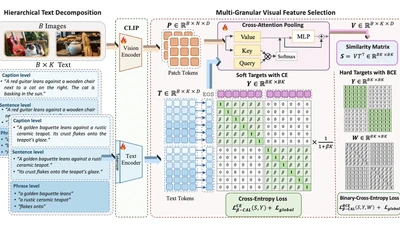
Beta-CLIP: Text-Conditioned Contrastive Learning for Multi-Granular Vision-Language Alignment
CLIP achieves strong zero-shot image-text retrieval by aligning global vision and text representations, yet it falls behind on fine-grained tasks even when fine-tuned on long, …
Fatimah zohra