SMILE: Infusing Spatial and Motion Semantics in Masked Video Learning
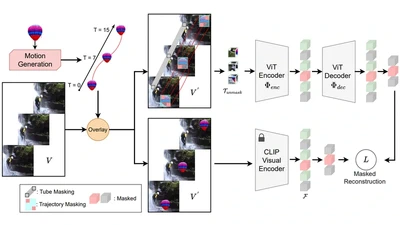
Masked video modeling, such as VideoMAE, is an effective paradigm for video self-supervised learning (SSL). However, they are primarily based on reconstructing pixellevel details …
Fida mohammad thoker
