End-to-End Temporal Action Detection with 1B Parameters Across 1000 Frames
November 29, 2023·
, ·
0 min read
·
0 min read
Shuming liu
Chen lin zhang
Chen Zhao
†
,Bernard ghanem
Abstract
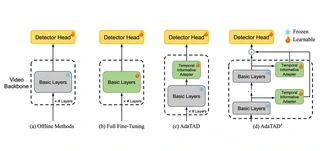
Recently, temporal action detection (TAD) has seen significant performance improvement with end-to-end training. However, due to the memory bottleneck, only models with limited scales and limited data volumes can afford end-to-end training, which inevitably restricts TAD performance. In this paper, we reduce the memory consumption for end-to-end training, and manage to scale up the TAD backbone to 1 billion parameters and the input video to 1,536 frames, leading to significant detection performance. The key to our approach lies in our proposed temporal-informative adapter (TIA), which is a novel lightweight module that reduces training memory. Using TIA, we free the humongous backbone from learning to adapt to the TAD task by only updating the parameters in TIA. TIA also leads to better TAD representation by temporally aggregating context from adjacent frames throughout the backbone. We evaluate our model across four representative datasets. Owing to our efficient design, we are able to train end-to-end on VideoMAEv2-giant and achieve 75.4% mAP on THUMOS14, being the first end-to-end model to outperform the best feature-based methods.
Type
Publication
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Deep Learning
Computer Vision
Video Understanding
Temporal Action Detection
Memory-Efficient Finetuning
Authors
Authors

Authors