Beta-CLIP: Text-Conditioned Contrastive Learning for Multi-Granular Vision-Language Alignment
February 21, 2026·
 ,·
0 min read
,·
0 min read
Fatimah zohra
Chen Zhao
†
,Hani itani
Bernard ghanem
Abstract
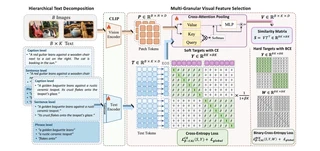
CLIP achieves strong zero-shot image-text retrieval by aligning global vision and text representations, yet it falls behind on fine-grained tasks even when fine-tuned on long, detailed captions. In this work, we propose beta-CLIP, a multi-granular text-conditioned contrastive learning framework designed to achieve hierarchical alignment between multiple textual granularities-from full captions to sentences and phrases-and their corresponding visual regions. For each level of granularity, beta-CLIP utilizes cross-attention to dynamically pool image patches, producing contextualized visual embeddings. To address the semantic overlap inherent in this hierarchy, we introduce the beta-Contextualized Contrastive Alignment Loss (beta-CAL). This objective parameterizes the trade-off between strict query-specific matching and relaxed intra-image contextualization, supporting both soft Cross-Entropy and hard Binary Cross-Entropy formulations. Through extensive experiments, we demonstrate that beta-CLIP significantly improves dense alignmentv – achieving 91.8% T2I 92.3% I2T at R@1 on Urban1K and 30.9% on FG-OVD (Hard), setting state-of-the-art among methods trained without hard negatives. beta-CLIP establishes a robust, adaptive baseline for dense vision-language correspondence. The code and models are released at https://github.com/fzohra/B-CLIP.
Type
Publication
arXiv preprint arXiv:2512.12678, 2026
