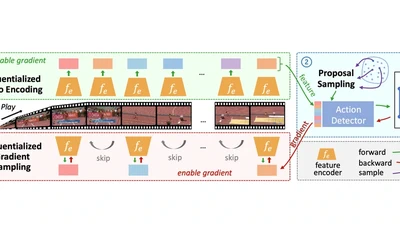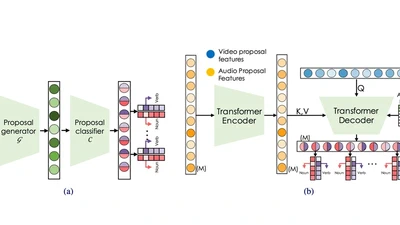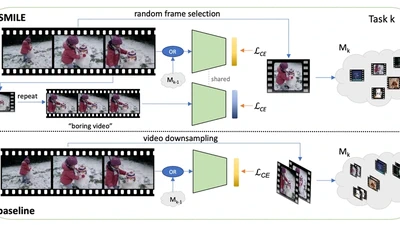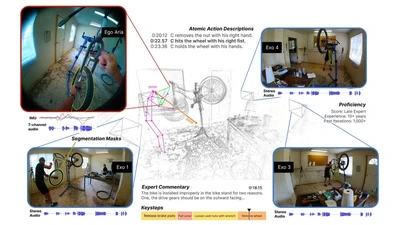
Ego-Exo4D: Understanding Skilled Human Activity from First-and Third-Person Perspectives
We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric …