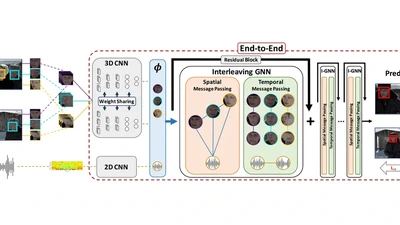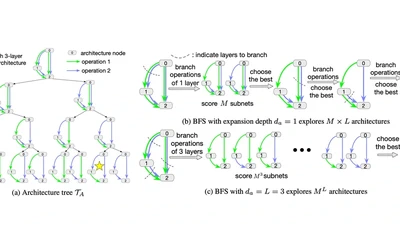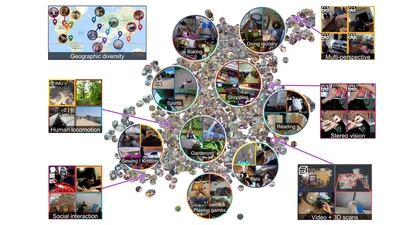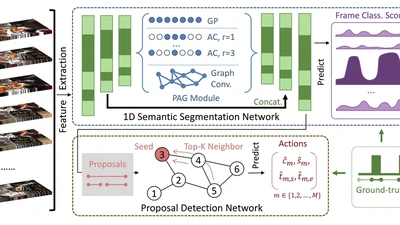
R-DFCIL: Relation-Guided Representation Learning for Data-Free Class Incremental Learning
Class-Incremental Learning(CIL) struggles with catastrophic forgetting when learning new knowledge, and Data-Free CIL (DFCIL) is even more challenging without access to the …
Qiankun gao