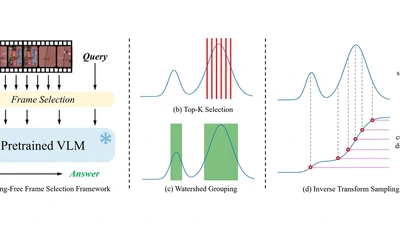
BOLT: Boost Large Vision-Language Model Without Training for Long-form Video Understanding
Large video-language models (VLMs) have demonstrated promising progress in various video understanding tasks. However, their effectiveness in long-form video analysis is …
Shuming liu